
Yuhang Hu (胡宇航)
👨🎓 PhD, Creative Machines Lab, Columbia University (advised by Prof. Hod Lipson)
👨💼 Founder & CEO/CTO, AheadForm Inc. (首形科技)
🔬 Research Focus
My research revolves around robotics and artificial intelligence, with key interests in:
- 🤖 Humanoid robots (legged robot, face robot and robot arm)
- 🔄 Self-supervised Learning and Self-modeling robots
- 🧠 Vision-Based Robotic Control – enabling robots to perceive their environment and their own body through cameras (often egocentric), allowing them to learn and adapt in a self-supervised manner.
🚀 Research Highlights
✨ Here are some of my key projects and contributions:
-
Facial Robots 🎭
Developed facial robots capable of dynamic human-like expressions through soft-skin modeling and self-supervised learning. -
Self-Supervised Learning Framework 🧑💻
Designed a system that enables large models to:- 🛠️ Identify robot configurations
- 👁️ Control legged robots using egocentric visual self-models
- 🧹 Understand and tidy messy environments by grasping the concept of tidiness
🌍 Vision
My long-term ambition is to enable robots to become lifelong learning machines through self-supervision. This vision aims to empower robots to:
- ⚙️ Adapt quickly to new environments
- 🔄 Transfer skills across different robotic platforms
- 📚 Continuously acquire new abilities—just like humans
🔥 News

Science Robotics Cover
Humanoid Robots. During verbal communication, humans easily perceive when speech does not match lip motion, leading to an uncanny feeling toward humanoid robots with simplistic lip movements. Hu et al. designed a face robot covered in a soft silicone skin that achieves high–degree-of-freedom lip actuation, enabling distinct lip shapes that cover 24 consonants and 16 vowels. By combining a self-supervised learning pipeline with a facial action transformer, the robot successfully matched motor commands with audio input for lip-audio synchronization. This month’s cover is an image of the face robot mid-speech with parted lips.

‘Consciousness’ in Robots Was Once Taboo. Now It’s the Last Word.
📝 Publications

Learning realistic lip motions for humanoid face robots
Getting lip motion right is one of the hardest problems in face robots. Humans are extremely sensitive to tiny errors in mouth timing and shape, which makes rule-based phoneme–viseme systems brittle and unnatural. In this work, we treat lip motion as a physically constrained, high-dimensional motor behavior, and approach it from a self-supervised learning perspective.
The robot first learns itself by watching its own face, building a self-model of what motions are actually executable on its hardware. It then learns from humans, transferring cross-lingual speech–lip regularities into its own motor space. A Facial Action Transformer maps latent facial representations to coordinated motor commands. The result: stable, natural lip synchronization on a real humanoid face robot across 11 languages—without hand-crafted rules.
Yuhang Hu, Jiong Lin, Judah Allen Goldfeder, Philippe M. Wyder, Yifeng Cao, Steven Tian, Yunzhe Wang, Jingran Wang, Mengmeng Wang, Jie Zeng, Cameron Mehlman, Yingke Wang, Delin Zeng, Boyuan Chen, Hod Lipson

Knolling Bot: Teaching Robots the Human Notion of Tidiness
🤖 Attention busy people! Imagine you are very busy and don’t have time to tell the robot where everything should be placed!🧹 So, don’t you think robots need to understand tidiness? 🤔
This paper📑 shows how robots can learn the concept of “knolling” from tidy demonstrations, allowing them to automatically organize your table in a neat and efficient way. 🧹✨
Yuhang Hu, Judah Goldfeder, Zhizhuo Zhang, Xinyue Zhu, Ruibo Liu, Philippe Wyder, Hod Lipson

Teaching Robots to Build Simulations of Themselves
Robots now use raw video to build kinematic self-awareness, similar to how humans learn to dance by watching their mirror reflection. Our goal is a robot that understands its own body, adapts to damage, and learns new skills without constant human programming. In the new study, we developed a way for robots to autonomously model their 3D shapes using a single regular 2D camera. This breakthrough was driven by three brain-mimicking AI systems known as deep neural networks. These inferred 3D motion from 2D video, enabling the robot to understand and adapt to its movements. The new system could also identify alterations to the bodies of the robots, such as a bend in an arm, and help them adjust their motions to recover from this simulated damage.
Yuhang Hu, Jiong Lin, Hod Lipson
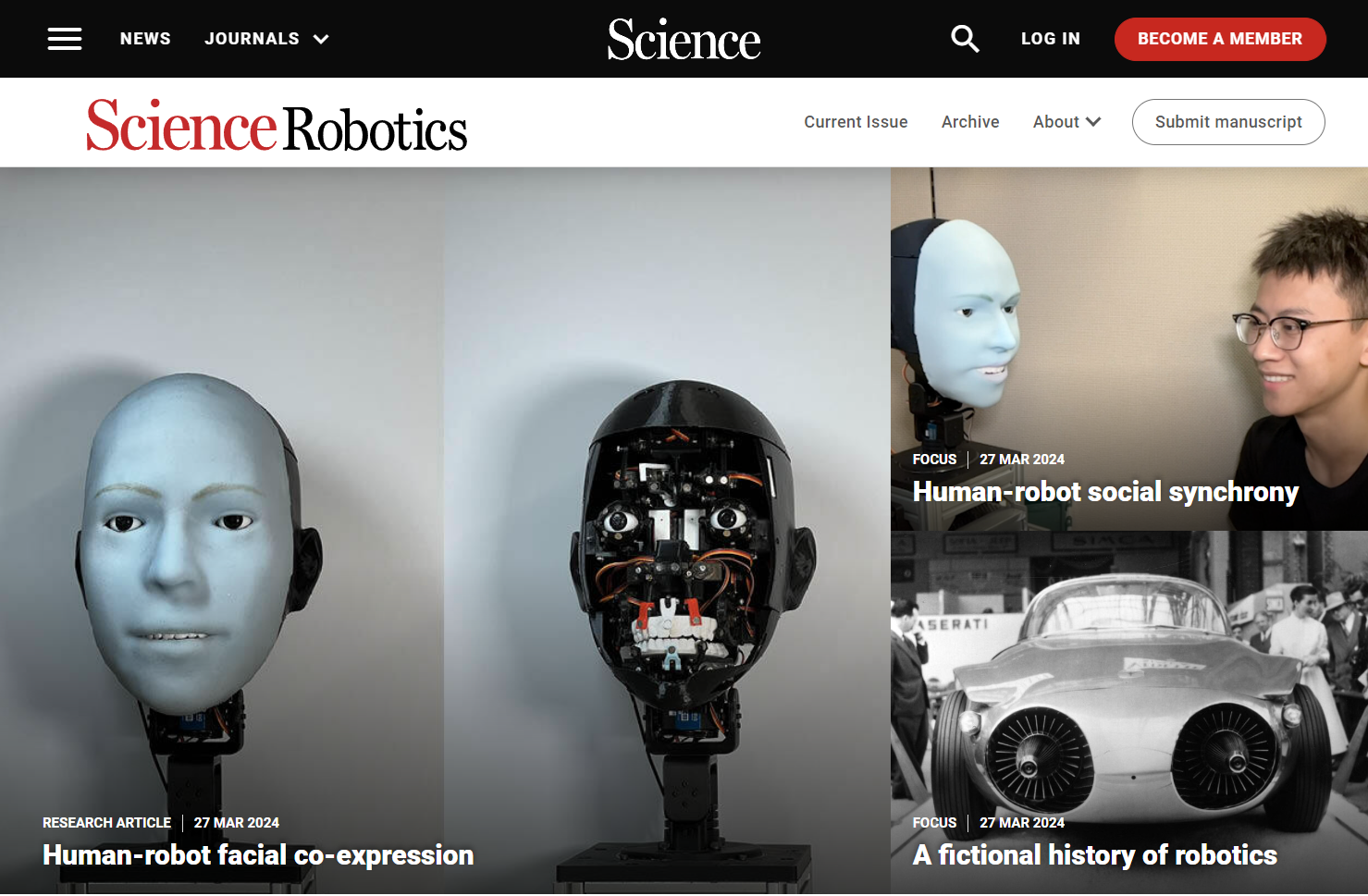
Human-robot facial coexpression
Humanoid robots are capable of mimicking human expressions by perceiving human emotions and responding after the human has finished their expression. However, a delayed smile can feel artificial and disingenuous compared with a smile occurring simultaneously with a companion’s smile. We trained our anthropomorphic facial robot named Emo to display an anticipatory expression to match its human companion. Emo is equipped with 26 motors and flexible silicone skin to provide precise control over its facial expressions. The robot was trained with a video dataset of humans making expressions. By observing subtle changes in a human face, the robot could predict an approaching smile 839 milliseconds before the human smiled and adjust its face to smile simultaneously.
Yuhang Hu, Boyuan Chen, Jiong Lin, Yunzhe Wang, Yingke Wang, Cameron Mehlman, Hod Lipson

Egocentric Visual Self-Modeling for Autonomous Robot Dynamics Prediction and Adaptation
We developed an approach that allows robots to learn their own dynamics using only a first-person camera view, without any prior knowledge! 🎥💡
🦿 Tested on a 12-DoF robot, the self-supervised model showcased the capabilities of basic locomotion tasks.
🔧 The robot can detect damage and adapt its behavior autonomously. Resilience! 💪
🌍 The model proved its versatility by working across different robot configurations!
🔮 This egocentric visual self-model could be the key to unlocking a new era of autonomous, adaptable, and resilient robots.
Yuhang Hu, Boyuan Chen, Hod Lipson

Mini Bidedal Robot
Design a legged robot starting from scratch, including CAD, electronics, embedding system, and deep reinforcement learning.
Yuhang Hu
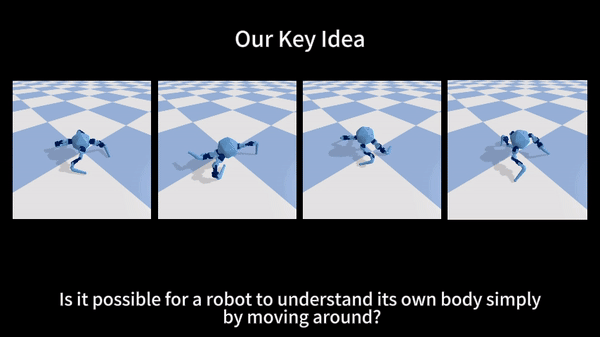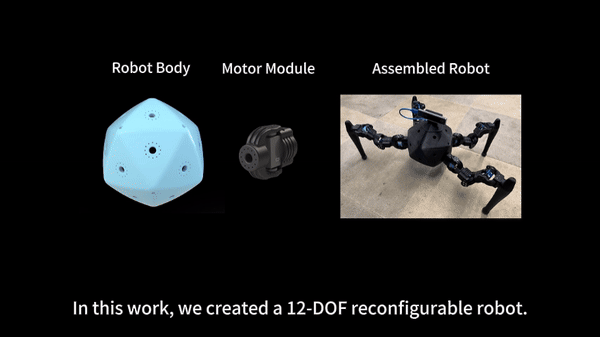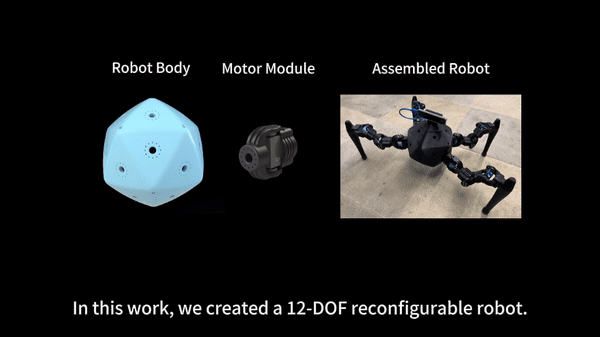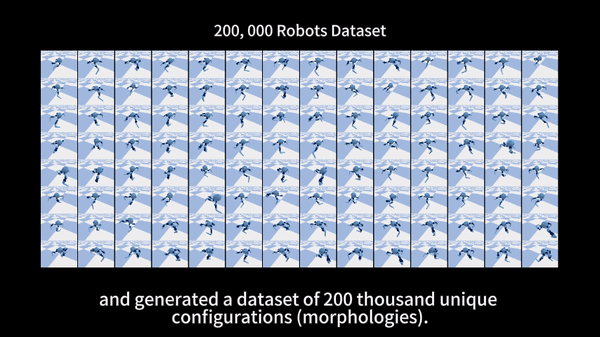
Reconfigurable Robot Identification from Motion Data
Can a robot autonomously understand and adapt to its physical form and functionalities through interaction with its environment? This question underscores the transition towards developing self-modeling robots without reliance on external sensory or pre-programmed knowledge about their structure. Here, we propose a meta- self-modeling that can deduce robot morphology through proprioception-the robot’s internal sense of its body’s position and movement. Our study introduces a 12-DoF reconfigurable legged robot, accompanied by a diverse dataset of 200k unique configurations, to systematically investigate the relationship between robotic motion and robot morphology.
Yuhang Hu, Yunzhe Wang, Ruibo Liu, Zhou Shen, Hod Lipson

Enhancing Object Organization with Self-supervised Graspability Estimation
A robotic system that integrates visual perception, a self-supervised graspability estimation model, knolling models, and robot arm controllers to efficiently organize an arbitrary number of objects on a table, even when they are closely clustered or stacked.
Yuhang Hu, Zhizhuo Zhang, Hod Lipson


Visual perspective taking for opponent behavior modeling
Humans learn at a young age to infer what others see and cannot see from a different point-of-view, and learn to predict others’ plans and behaviors. These abilities have been mostly lacking in robots, sometimes making them appear awkward and socially inept. Here we propose an end-to-end long-term visual prediction framework for robots to begin to acquire both these critical cognitive skills, known as Visual Perspective Taking (VPT) and Theory of Behavior (TOB).
Boyuan Chen, Yuhang Hu, Robert Kwiatkowski, Shuran Song, Hod Lipson

Multiplexed reverse-transcriptase quantitative polymerase chain reaction using plasmonic nanoparticles for point-of-care COVID-19 diagnosis
Quantitative polymerase chain reaction (qPCR) offers the capabilities of real-time monitoring of amplified products, fast detection, and quantitation of infectious units, but poses technical hurdles for point-of-care miniaturization compared with end-point polymerase chain reaction. Here we demonstrate plasmonic thermocycling, in which rapid heating of the solution is achieved via infrared excitation of nanoparticles, successfully performing reverse-transcriptase qPCR (RT-qPCR) in a reaction vessel containing polymerase chain reaction chemistry, fluorescent probes and plasmonic nanoparticles. The method could rapidly detect SARS-CoV-2 RNA from human saliva and nasal specimens with 100% sensitivity and 100% specificity, as well as two distinct SARS-CoV-2 variants.
Nicole R Blumenfeld, Michael Anne E Bolene, Martin Jaspan, Abigail G Ayers, Sabin Zarrandikoetxea, Juliet Freudman, Nikhil Shah, Angela M Tolwani, Yuhang Hu, Terry L Chern, James Rogot, Vira Behnam, Aditya Sekhar, Xinyi Liu, Bulent Onalir, Robert Kasumi, Abdoulaye Sanogo, Kelia Human, Kasey Murakami, Goutham S Totapally, Mark Fasciano, Samuel K Sia